Report on the case of double descent in active learning
Double descent was first investigated by OpenAI in 2019. They have also published their hypothesis on why double descent happens in some training tasks, in this paper.
During our first rounds of experiments with MCDropout for active learning, we came around double descent incident in several cases and hence, it was all the reason to figure out why and when it happens. Double descent is harmful to the active learning procedure as it is a sign that the model did not learn the current labelled set properly and therefore the next set of uncertainties would not be valid.
A combination of several conditions and hyper-parameters could result in a double descent. Below, we will define each condition/hyper-parameter, and then we describe what combinations would result in double descent occurrence. We will end this blog post with our hypothesis as to why double descent happens in each case.
Training Condition
Early Stopping
While early stopping helps prevent overfitting, experiments show that in the case of active
learning early stopping along with other conditions would result in the negative effect of double descent. In our
experiments, the trials which are tested using early stopping are marked by lbw: Y and p will define the number of
patience epochs to make sure that the loss is not oscillating.
Resetting the weights of the model
During active learning, we reset the model weights to some initial/random weights after
each active learning step, so that the model is ready to learn from the new distribution of labelled samples without
the prior bias of the previous distribution of labelled samples. In this paper, it is shown that the last few layers have the most influential weights for estimating model uncertainty in Bayesian neural architecture, and hence, we have made it possible in our pipeline to do active learning with only resetting the weights for the
last few layers of a network. In this study, you will see if taken proper measurements resetting only the linear layers could be enough for removing this prior bias, and hence, it would speed up the process by
not forcing the model to learn from scratch. However, depending on whether we are using early stopping or not this can
introduce double descent and be harmful to the procedure. In our experiments
rs: full defines, resetting the model weights to their initial weights and rs: partial indicates resetting the
weights of the linear layers only.
Hyper-parameters
Weight decay
The different set of experiments are tested also with different weight decays and in some cases, changing the weight
decay could prevent double descent. Weight decay parameter value is marked as wd.
Experiments and analysis
We ran 4 categories of experiments: Dataset: CIFAR10 Model: Vgg16 trained on imagenet
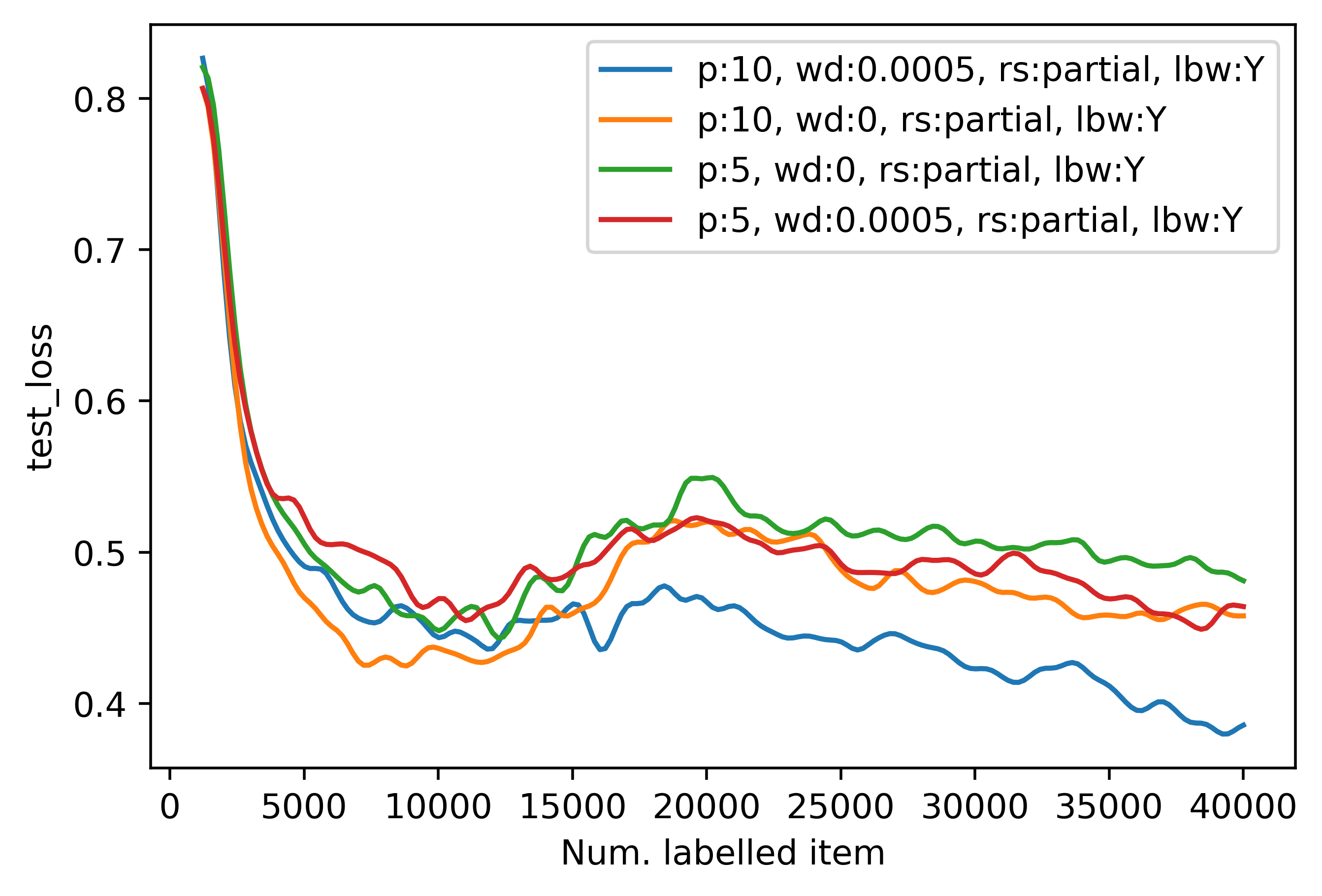
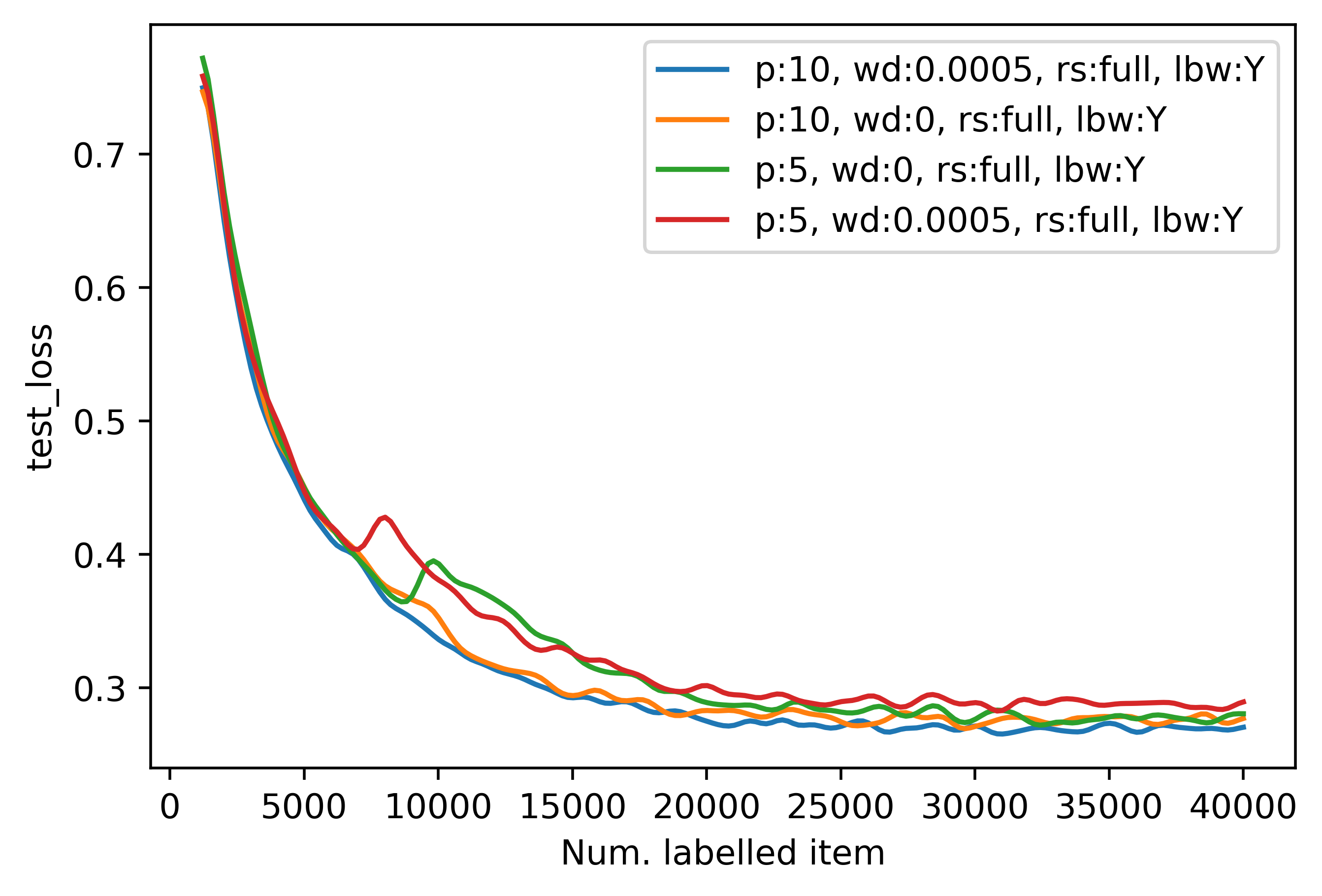
In the first two experiments, if we are using early stopping, the partial reset will provoke a double descent. A closer
look in the second diagram shows that although in the case of fully resetting the model weights, we can prevent the
double descent phenomenon, it is highly dependent on the number of patience epochs p. In the case of early stopping,
one shall give the model enough time to learn and stabilize before stopping the training in each active learning step.
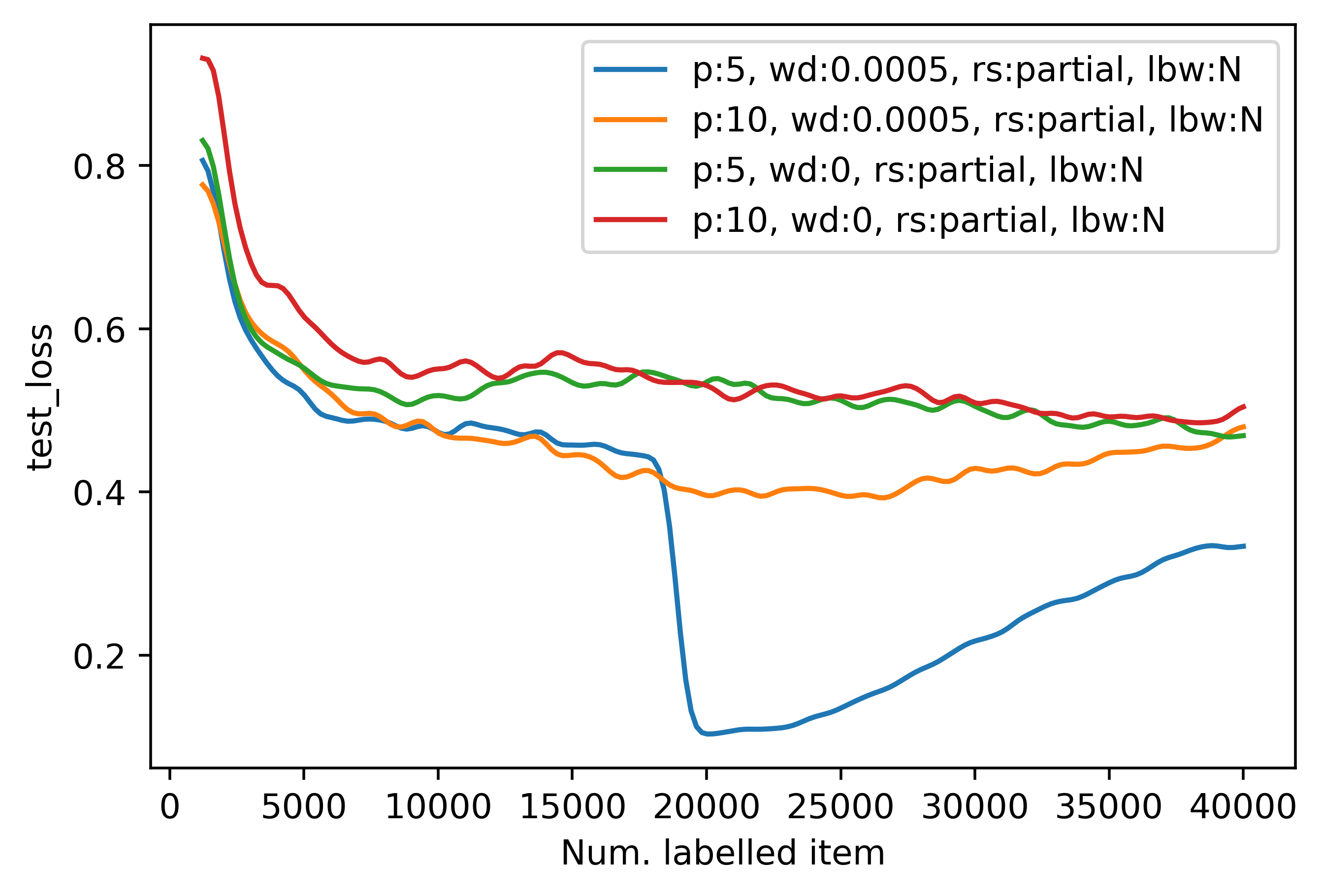
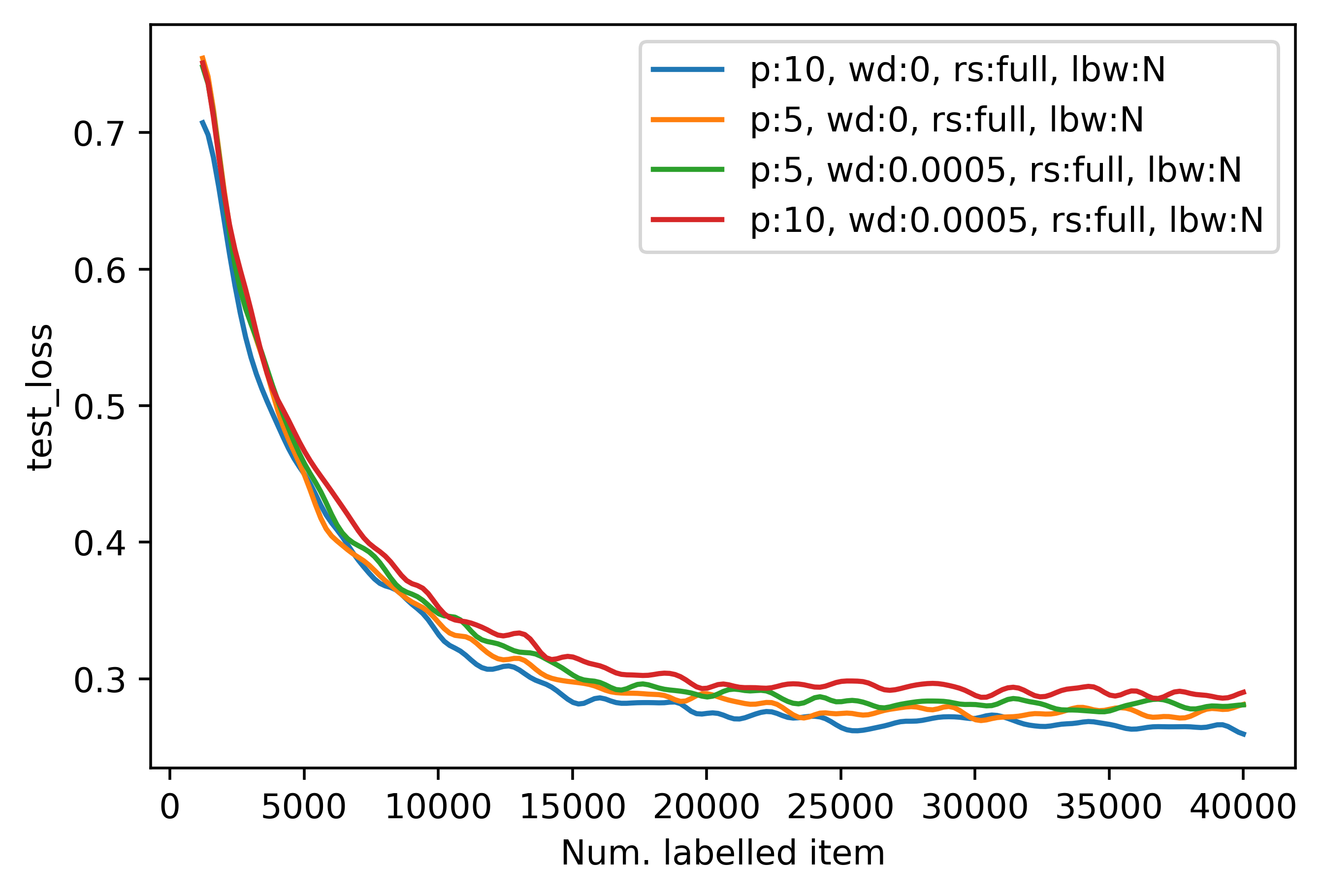
Moving to the last two experiments, we show that not using early stopping results in smoother active training. The first
graph shows us that using partial resetting could be very tricky for active learning. To prevent double
descent and hence a smooth training with partial resetting, proper tuning the model using regularization methods such as
weight_decay is a necessity. In our case, if we don't use weight decay, the double descent still will happen although
with a negligible peak. Moreover, letting the model train well before performing uncertainty estimation is another
key to encourage smooth training, we show the difference between letting the model to train for 10 epochs vs 5 epochs
before adding samples to the labelled set.
Note
In the case of not using early stopping, p is used to show the number of epochs we train the model before
estimating uncertainties and increase the labelled set.
All in all, not using early stopping and fully resetting the model weights i.e. the last graph, could certify a smooth
training procedure without being worried about other elements such as weight decay.
Our Hypothesis
After analysing the results of our experiments, we tend to agree with OpenAI on the hypothesis as to why double descent might happen. However, the case of active learning is more complex as the dataset gets more and more complex after each active learning step. Even though we do not change the model architecture, we do reset the model weights, so that the model can fit the new dataset again from scratch.
On the other hand, active learning is an expensive procedure and sometimes we need to minimize this cost by resetting only parts of the model weights. This of course would lead to the model having difficulty to learn as we grow the dataset, and as OpenAI reports, "adding more data is harmful to the training". However, we hypothesise that it is still possible to minimize the cost of training using partial resetting if one uses early stopping and closely track the model training to tune the weight decay properly and hence lead the model to smoothly get adjusted to the new dataset at each active learning step. We argue that this is the best way of getting a competing loss while reducing the cost of active learning.
Author(s)
- Parmida Atighehchian
- Frédéric Branchaud-Charron
Note to our readers
As we are excited to share our experiments and hypotheses with you, we do not claim that this report is satisfactory. Therefore, we would encourage our Baal users to help us spread informations and results on this particular problem. Please contact us if you make further discovery on this important question.